Eine Zufallsvariable ist eine Funktion. Eine was?! Ja, genau. Auch noch eine deterministische und etwas unerwartet auch kein bisschen zufällig. Dabei ist ziemlich egal von welchem Raum in welchen Raum die Zufallsvariable abbildet. Ich wähle einmal ein Beispiel:
Unsere Zufallsvariable heiße X. Die Zufallsvariable X bildet vom Raum
A={1,2,3}
in den Raum
B={W,L}
ab. Dabei ist W ein Walross und L ein Leopard. Was ich sagen will ist: Zufallsvariablen operieren auf Räumen, die nicht algebraisch sein müssen. Eine Zufallsvariable kann irgendwas auf irgendwas abbilden.
Wir können Zufallsvariablen an einem Beispiel gut untersuchen. Wir definierne X wie folgt:
X(1) = W, X(2) = W, X(3) = L.
Aber wo ist denn da der Zufall?! Es gibt keinen. Stochastik ist reine Mathematik, Mathematik über Funktionen auf Räumen und deren Eigenschaften. Die Räume eignen sich besonders gut, um damit reale, zufällige Ereignisse zu beschreiben. Wenn man das tut betreibt man Statistik. In unserem Beispiel könnte ich zur Veranschaulichung behaupten, dass A die Tore in einer Spielshow sind B sind die Dinge, die man hinter den Toren finden kann. Aber es würde der Situation nichts hinzufügen.
Was man in der Stochastik wirklich tut ist messen. Man braucht für jeden Raum A und B noch ein Maßband, mit dem wir Untermengen a⊂A und b⊂B ausmessen können. Man sagt "Wahrscheinlichkeit", aber in Wahrheit misst man nur aus. Damit meine ich: man gibt die Größe an. Wie mit einem Zollstock. Wenn Stochastiker sagen: Die Wahrscheinlichkeit ist 1/3! Dann meinen sie: Ich habe einen Zollstock genommen und gemessen, und es ist 1/3 groß. Zur allgemeinen Verwirrung nennen wir dieses Maßband "Wahrscheinlichkeitsmaß", obwohl daran wieder nichts zufällig ist.
Ich definiere nun ein Maßband für A, aber keins für B (wir suchen später ein Maßband für B, versprochen). Ich nenne mein Maßband P. Und ich sage P({1})=1/3. P({2})=1/3. P({3})=1/3. P ist die Gleichverteilung auf A. Vielleicht fällt einem Adlerauge auf, dass P eigentlich alle Untermengen a⊂A messen können sollte, was ist beispielsweise P({1,2})? Es ist die Eigenschaft von Maßbändern, dass man auch die Einzelteile allein messen kann um dann die Längen aufzusummieren.
P({1,2}) = P({1}) + P({2}) = 2/3.
Wie gesagt, die Stochastik ist groß darin, zu messen, und wir haben B noch nicht ausgemessen. Die, wenn man so will, zentrale Eigenschaft der Stochastik ist, dass wenn man A messen kann und man eine Zufallsvariable von A nach B hat, dann können wir uns ein Maß für B bauen. Stochastiker beschreiben dieses abgeleitete Maßband durch eine Notation, die nur erfunden scheint um völlig anders auszusehen als der Rest der Mathematik. Sie schreiben Dinge wie P(X=L). Was soll das heißen? (Die meisten Studenten helfen sich, indem sie den Ausdruck metaphorisch verstehen und lesen: "Wahrscheinlichkeit, dass X=L ist") Ich benutze hier eine gewöhnlichere Notation und erkläre dann die Stochastikernotation später.
Ok, wir suchen ein Maß für B. Wir haben P, das ist das Maß für A, und wir haben X, die Zufallsvariable. Ich schlage als Maßband auf B die Funktion
 vor. Die -1 im Exponenten bedeutet Umkehrfunktion (siehe etwa hier), der Zirkel bedeutet "nach" und ich meine damit nur
vor. Die -1 im Exponenten bedeutet Umkehrfunktion (siehe etwa hier), der Zirkel bedeutet "nach" und ich meine damit nur  .
.Damit wir die Situation besser verstehen können wir
ausrechnen.X-1({W}) sind alle Urbilder von Walross, das heißt
X-1({W}) = {1,2}.
Und also
 ,
,und analog
 .
.Unser Ziel war, ein Maßband für B zu haben, haben wir es erreicht? Es gibt zwei wichtige Kriterien für ein gutes Maßband in der Stochastik. Da nennt man sie "Wahrscheinlichkeitsmaße". Die erste ist:
- Wenn man den ganzen Raum misst, so erhält man als Ergebnis 1
Das haben wir in unserem Beispiel erreicht, denn 2/3 + 1/3 = 1. Es gilt für alle über Wahrscheinlichkeitsvariablen induzierte Maße, und ich empfehle dem geneigten Leser das zu beweisen, es ist wirklich leicht :).
Die zweite ist:
- Wenn wir etwas messen, dann können wir es auch gerade so gut in Teile zersägen, die Teile messen, und deren Summen müssen das Ganze ergeben
Wikipedia drückt etwas weniger prosaisch so aus:
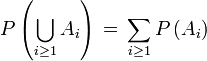 , mit Ai paarweise disjunkt.
, mit Ai paarweise disjunkt.Und hier müsste man ein wenig weiter ausholen, ich gebe nur eine Kurzfassung: Es ist eine traurige Realität der Mathematik, dass man Wahrscheinlichkeitsräume nicht beliebig zersägen kann. In unseren ziemlich kleinen Wahrscheinlichkeitsräumen ist alles noch Spaß und möglich, aber schon bei nur leicht komplizierteren Räumen muss man die meisten mathematisch möglichen Zersägungen ausschließen, um das erste Kriterium zu erfüllen. Man muss also neben einem Wahrscheinlichkeitsraum auch eine Liste seiner erlaubten Zersägungen angeben. Diese Liste der erlaubten Zersägungen nennt man die "σ-Algebra" des Wahrscheinlichkeitsraums. Die σ-Algebra irgend eines Wahrscheinlichkeitsraums C enthält also nur die Untermengen von C, die wir auch messen können.
Und jetzt können wir endlich erklären, was eine Wahrscheinlichkeitsvariable ist :). Eine Funktion X: A→B ist eine Wahrscheinlichkeitsvariable wenn man aus ihr auf B ein Wahrscheinlichkeitsmaß erzeugen kann. Warum sollte das nicht möglich sein? Nun, wenn X bezüglich der σ-Algebren "inkompatibel" ist.
Ein Beispiel: nehmen wir an, wir kennen ein Wahrscheinlichkeitsmaß auf A, nämlich P.
Dann hätten wir gern, dass
ein Wahrscheinlichkeitsmaß ist. Warum sollte es das nicht sein? Nun, X-1 könnte ein Bild haben, das kein gültiges Argument für P ist (gülte Argumente für P sind gültige "Zersägungen" von A, und das sind Elemente der σ-Algebra zu A). Und das ist schon die ganze Magie. Wir verlangen, dass X-1, gültige Zersägungen von B auf gültige Zersägungen von A abbildet. Oder formalistischer, wobei das kalligraphische A die σ-Algebra zu A ist, das kalligraphische B die σ-Algebra zu B: .
.Was einem auffallen sollte ist, dass diese Bedingung ziemlich mild ist. Man muss ziemlich weit gehen um eine Funktion zu finden, die die Bedingung nicht erfüllt (obwohl technisch gesehen fast alle Funktionen die Bedingung NICHT erfüllen).
Etliche Studenten werden mit dieser Bedingung konfrontiert und denken: Aha, X muss surjektiv sein! Aber X muss weder surjektiv noch injektiv sein. Mein geneigter Blog-Leser hat gelernt: die Bedingung drückt die Kompatibilität der σ-Algebren aus, sonst nichts.
Es ist noch etwas offen: Unsere Notation ist schwer zu tippen und zu schreiben. Und deswegen haben sich die Stochastiker eine Spezialnotation ausgedacht, die gegen alle Konventionen der Mathematik geht, aber sehr viel kürzer ist als meine und deswegen beliebt:

Naja, und außerdem ist die Schreibweise suggestiv. P(X=b) liest man zu gern als: Wahrscheinlichkeit, dass X=b ist, was cool klingt, und auch gut zur Intuition über Wahrscheinlichkeiten passt, aber es passt eben nicht so gut zur Definitionswelt der Stochastik, in der X=b nicht zufällig ist.
Ich hoffe, dass nach diesem Artikel der geneigte Leser beides kann: die Definition für formale Beweise benutzen ohne die Intuition für Zufall zu verlieren, die jeder Student mitbringt :).

Ich habes wirklich versucht!
AntwortenLöschenDa ich deinem rat gefolgt bin blogs als RSS feeds zu speichern habe ich also sofort gesehen das du etwas neues gebloggt hast! Ich habe es nun drei mal probiert es zu lesen aber kein wort verstanden!^^
Lg